generated from fahricansecer/boilerplate-be
@@ -1,4 +1,5 @@
|
||||
// X to Markdown Service - Converts X/Twitter posts to markdown using baoyu skill
|
||||
// X to Markdown Service - Converts X/Twitter posts to markdown
|
||||
// Uses baoyu skill as primary, FXTwitter API as fallback
|
||||
// Path: src/modules/content-generation/services/x-to-markdown.service.ts
|
||||
|
||||
import { Injectable, Logger } from '@nestjs/common';
|
||||
@@ -23,14 +24,6 @@ export interface XToMarkdownResult {
|
||||
export class XToMarkdownService {
|
||||
private readonly logger = new Logger(XToMarkdownService.name);
|
||||
|
||||
// Path to the skill scripts directory — resolve relative to project root
|
||||
private readonly SKILL_DIR = path.resolve(
|
||||
process.cwd(),
|
||||
'../.agent/skills/baoyu-danger-x-to-markdown/scripts',
|
||||
);
|
||||
|
||||
private readonly MAIN_SCRIPT = path.join(this.SKILL_DIR, 'main.ts');
|
||||
|
||||
/**
|
||||
* Check if a URL is an X/Twitter URL
|
||||
*/
|
||||
@@ -52,7 +45,20 @@ export class XToMarkdownService {
|
||||
}
|
||||
|
||||
/**
|
||||
* Convert an X/Twitter URL to markdown using the baoyu skill
|
||||
* Extract tweet ID and username from X URL
|
||||
*/
|
||||
private parseTweetUrl(url: string): { username: string; tweetId: string } | null {
|
||||
// Match https://x.com/<user>/status/<id> or https://twitter.com/<user>/status/<id>
|
||||
const match = url.match(/(?:x\.com|twitter\.com)\/([^\/]+)\/status\/(\d+)/i);
|
||||
if (match) {
|
||||
return { username: match[1], tweetId: match[2] };
|
||||
}
|
||||
return null;
|
||||
}
|
||||
|
||||
/**
|
||||
* Convert an X/Twitter URL to markdown
|
||||
* Strategy: Try baoyu skill first, then FXTwitter API fallback
|
||||
*/
|
||||
async convertToMarkdown(url: string): Promise<XToMarkdownResult> {
|
||||
if (!this.isXUrl(url)) {
|
||||
@@ -64,53 +70,74 @@ export class XToMarkdownService {
|
||||
};
|
||||
}
|
||||
|
||||
// Check if skill script exists
|
||||
if (!fs.existsSync(this.MAIN_SCRIPT)) {
|
||||
this.logger.warn(`X-to-Markdown skill script not found at: ${this.MAIN_SCRIPT}`);
|
||||
// Try alternative paths
|
||||
const altPaths = [
|
||||
path.resolve(process.cwd(), '.agent/skills/baoyu-danger-x-to-markdown/scripts/main.ts'),
|
||||
path.resolve(process.cwd(), '../../.agent/skills/baoyu-danger-x-to-markdown/scripts/main.ts'),
|
||||
];
|
||||
|
||||
let found = false;
|
||||
for (const altPath of altPaths) {
|
||||
if (fs.existsSync(altPath)) {
|
||||
this.logger.log(`Found script at alternative path: ${altPath}`);
|
||||
return this.runScript(altPath, url);
|
||||
}
|
||||
}
|
||||
|
||||
if (!found) {
|
||||
return {
|
||||
success: false,
|
||||
markdown: '',
|
||||
url,
|
||||
error: `Skill script not found. Searched: ${this.MAIN_SCRIPT}, ${altPaths.join(', ')}`,
|
||||
};
|
||||
}
|
||||
// Try baoyu skill script first
|
||||
const scriptResult = await this.tryBaoyuScript(url);
|
||||
if (scriptResult.success && scriptResult.markdown) {
|
||||
return scriptResult;
|
||||
}
|
||||
|
||||
return this.runScript(this.MAIN_SCRIPT, url);
|
||||
this.logger.warn(`Baoyu script failed or returned empty: ${scriptResult.error}. Trying FXTwitter fallback...`);
|
||||
|
||||
// Fallback: FXTwitter API (public, no auth needed)
|
||||
const fxResult = await this.tryFxTwitter(url);
|
||||
if (fxResult.success) {
|
||||
return fxResult;
|
||||
}
|
||||
|
||||
this.logger.warn(`FXTwitter also failed: ${fxResult.error}. Trying syndication API...`);
|
||||
|
||||
// Fallback 2: Twitter syndication API
|
||||
const synResult = await this.trySyndication(url);
|
||||
if (synResult.success) {
|
||||
return synResult;
|
||||
}
|
||||
|
||||
return {
|
||||
success: false,
|
||||
markdown: '',
|
||||
url,
|
||||
error: `All methods failed. Baoyu: ${scriptResult.error}. FXTwitter: ${fxResult.error}. Syndication: ${synResult.error}`,
|
||||
};
|
||||
}
|
||||
|
||||
/**
|
||||
* Run the baoyu skill script to convert a URL to markdown
|
||||
* Try baoyu skill script
|
||||
*/
|
||||
private async runScript(scriptPath: string, url: string): Promise<XToMarkdownResult> {
|
||||
try {
|
||||
this.logger.log(`Converting X URL to markdown: ${url}`);
|
||||
private async tryBaoyuScript(url: string): Promise<XToMarkdownResult> {
|
||||
// Find the skill script
|
||||
const possiblePaths = [
|
||||
path.resolve(process.cwd(), '../.agent/skills/baoyu-danger-x-to-markdown/scripts/main.ts'),
|
||||
path.resolve(process.cwd(), '.agent/skills/baoyu-danger-x-to-markdown/scripts/main.ts'),
|
||||
path.resolve(process.cwd(), '../../.agent/skills/baoyu-danger-x-to-markdown/scripts/main.ts'),
|
||||
];
|
||||
|
||||
// Use npx -y bun to run the TypeScript script
|
||||
let scriptPath: string | null = null;
|
||||
for (const p of possiblePaths) {
|
||||
if (fs.existsSync(p)) {
|
||||
scriptPath = p;
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
if (!scriptPath) {
|
||||
return {
|
||||
success: false,
|
||||
markdown: '',
|
||||
url,
|
||||
error: 'Baoyu skill script not found',
|
||||
};
|
||||
}
|
||||
|
||||
try {
|
||||
this.logger.log(`Running baoyu script: ${scriptPath}`);
|
||||
const { stdout, stderr } = await execFileAsync(
|
||||
'npx',
|
||||
['-y', 'bun', scriptPath, url, '--json'],
|
||||
{
|
||||
timeout: 30000, // 30 second timeout
|
||||
maxBuffer: 1024 * 1024 * 5, // 5MB
|
||||
timeout: 30000,
|
||||
maxBuffer: 1024 * 1024 * 5,
|
||||
env: {
|
||||
...process.env,
|
||||
// Pass X auth tokens if set in environment
|
||||
X_AUTH_TOKEN: process.env.X_AUTH_TOKEN || '',
|
||||
X_CT0: process.env.X_CT0 || '',
|
||||
},
|
||||
@@ -118,50 +145,244 @@ export class XToMarkdownService {
|
||||
);
|
||||
|
||||
if (stderr) {
|
||||
this.logger.warn(`X-to-Markdown stderr: ${stderr.substring(0, 500)}`);
|
||||
this.logger.warn(`Baoyu stderr: ${stderr.substring(0, 300)}`);
|
||||
}
|
||||
|
||||
// Check for "Failed to fetch thread" in stdout
|
||||
if (stdout.includes('Failed to fetch thread') || stdout.includes('Failed to fetch')) {
|
||||
return {
|
||||
success: false,
|
||||
markdown: '',
|
||||
url,
|
||||
error: 'Baoyu script: Failed to fetch thread (API returned empty tweet_results)',
|
||||
};
|
||||
}
|
||||
|
||||
// Try to parse JSON output
|
||||
try {
|
||||
const result = JSON.parse(stdout.trim());
|
||||
this.logger.log(`Successfully converted X URL: ${url} (${result.markdown?.length || 0} chars)`);
|
||||
return {
|
||||
success: true,
|
||||
markdown: result.markdown || result.content || stdout,
|
||||
url,
|
||||
author: result.author,
|
||||
tweetCount: result.tweetCount,
|
||||
coverImage: result.coverImage,
|
||||
};
|
||||
if (result.markdown || result.content) {
|
||||
return {
|
||||
success: true,
|
||||
markdown: result.markdown || result.content || stdout,
|
||||
url,
|
||||
author: result.author,
|
||||
tweetCount: result.tweetCount,
|
||||
coverImage: result.coverImage,
|
||||
};
|
||||
}
|
||||
} catch {
|
||||
// If not valid JSON, the output is the markdown itself
|
||||
this.logger.log(`X-to-Markdown returned plain text (${stdout.length} chars)`);
|
||||
return {
|
||||
success: true,
|
||||
markdown: stdout.trim(),
|
||||
url,
|
||||
};
|
||||
// Check if output is actually markdown content
|
||||
if (stdout.trim().length > 50 && !stdout.includes('Failed')) {
|
||||
return {
|
||||
success: true,
|
||||
markdown: stdout.trim(),
|
||||
url,
|
||||
};
|
||||
}
|
||||
}
|
||||
} catch (error: any) {
|
||||
this.logger.error(`Failed to convert X URL: ${url}`, error.message);
|
||||
|
||||
// If the script fails, try a simpler fallback approach
|
||||
return this.fallbackScrape(url);
|
||||
return {
|
||||
success: false,
|
||||
markdown: '',
|
||||
url,
|
||||
error: `Baoyu script returned no content: ${stdout.substring(0, 200)}`,
|
||||
};
|
||||
} catch (error: any) {
|
||||
return {
|
||||
success: false,
|
||||
markdown: '',
|
||||
url,
|
||||
error: `Baoyu script error: ${error.message}`,
|
||||
};
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Fallback: If the baoyu script fails, try a basic scrape
|
||||
* using the existing WebScraperService pattern
|
||||
* Fallback: Use FXTwitter API (public, no auth required)
|
||||
* https://github.com/FixTweet/FxTwitter
|
||||
*/
|
||||
private async fallbackScrape(url: string): Promise<XToMarkdownResult> {
|
||||
this.logger.warn(`Using fallback scrape for X URL: ${url}`);
|
||||
return {
|
||||
success: false,
|
||||
markdown: '',
|
||||
url,
|
||||
error: 'Script execution failed. X auth tokens may be needed. Set X_AUTH_TOKEN and X_CT0 environment variables.',
|
||||
};
|
||||
private async tryFxTwitter(url: string): Promise<XToMarkdownResult> {
|
||||
const parsed = this.parseTweetUrl(url);
|
||||
if (!parsed) {
|
||||
return { success: false, markdown: '', url, error: 'Cannot parse tweet URL' };
|
||||
}
|
||||
|
||||
try {
|
||||
const apiUrl = `https://api.fxtwitter.com/${parsed.username}/status/${parsed.tweetId}`;
|
||||
this.logger.log(`Trying FXTwitter API: ${apiUrl}`);
|
||||
|
||||
const response = await fetch(apiUrl, {
|
||||
headers: {
|
||||
'User-Agent': 'ContentHunter/1.0',
|
||||
'Accept': 'application/json',
|
||||
},
|
||||
signal: AbortSignal.timeout(15000),
|
||||
});
|
||||
|
||||
if (!response.ok) {
|
||||
return {
|
||||
success: false,
|
||||
markdown: '',
|
||||
url,
|
||||
error: `FXTwitter API returned ${response.status}`,
|
||||
};
|
||||
}
|
||||
|
||||
const data = await response.json();
|
||||
const tweet = data?.tweet;
|
||||
|
||||
if (!tweet || !tweet.text) {
|
||||
return {
|
||||
success: false,
|
||||
markdown: '',
|
||||
url,
|
||||
error: 'FXTwitter returned no tweet content',
|
||||
};
|
||||
}
|
||||
|
||||
// Build markdown from FXTwitter response
|
||||
const markdown = this.buildMarkdownFromFxTweet(tweet, url);
|
||||
|
||||
return {
|
||||
success: true,
|
||||
markdown,
|
||||
url,
|
||||
author: tweet.author?.name
|
||||
? `${tweet.author.name} (@${tweet.author.screen_name})`
|
||||
: `@${parsed.username}`,
|
||||
tweetCount: 1,
|
||||
coverImage: tweet.media?.photos?.[0]?.url || tweet.author?.avatar_url,
|
||||
};
|
||||
} catch (error: any) {
|
||||
return {
|
||||
success: false,
|
||||
markdown: '',
|
||||
url,
|
||||
error: `FXTwitter error: ${error.message}`,
|
||||
};
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Fallback 2: Use Twitter syndication API (embed data)
|
||||
*/
|
||||
private async trySyndication(url: string): Promise<XToMarkdownResult> {
|
||||
const parsed = this.parseTweetUrl(url);
|
||||
if (!parsed) {
|
||||
return { success: false, markdown: '', url, error: 'Cannot parse tweet URL' };
|
||||
}
|
||||
|
||||
try {
|
||||
const apiUrl = `https://cdn.syndication.twimg.com/tweet-result?id=${parsed.tweetId}&lang=en&token=x`;
|
||||
this.logger.log(`Trying syndication API: ${apiUrl}`);
|
||||
|
||||
const response = await fetch(apiUrl, {
|
||||
headers: {
|
||||
'User-Agent': 'Mozilla/5.0 (compatible; ContentHunter/1.0)',
|
||||
'Accept': 'application/json',
|
||||
},
|
||||
signal: AbortSignal.timeout(10000),
|
||||
});
|
||||
|
||||
if (!response.ok) {
|
||||
return {
|
||||
success: false,
|
||||
markdown: '',
|
||||
url,
|
||||
error: `Syndication API returned ${response.status}`,
|
||||
};
|
||||
}
|
||||
|
||||
const data = await response.json();
|
||||
if (!data?.text) {
|
||||
return {
|
||||
success: false,
|
||||
markdown: '',
|
||||
url,
|
||||
error: 'Syndication API returned no text',
|
||||
};
|
||||
}
|
||||
|
||||
// Build markdown from syndication data
|
||||
const author = data.user?.name
|
||||
? `${data.user.name} (@${data.user.screen_name})`
|
||||
: `@${parsed.username}`;
|
||||
|
||||
let markdown = `---\nurl: "${url}"\nauthor: "${author}"\n---\n\n`;
|
||||
markdown += data.text;
|
||||
|
||||
if (data.mediaDetails) {
|
||||
markdown += '\n\n';
|
||||
for (const media of data.mediaDetails) {
|
||||
if (media.type === 'photo') {
|
||||
markdown += `\n`;
|
||||
} else if (media.type === 'video') {
|
||||
const bestVariant = media.video_info?.variants
|
||||
?.filter((v: any) => v.content_type === 'video/mp4')
|
||||
?.sort((a: any, b: any) => (b.bitrate || 0) - (a.bitrate || 0))?.[0];
|
||||
if (bestVariant) {
|
||||
markdown += `[Video](${bestVariant.url})\n`;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return {
|
||||
success: true,
|
||||
markdown,
|
||||
url,
|
||||
author,
|
||||
tweetCount: 1,
|
||||
coverImage: data.mediaDetails?.[0]?.media_url_https || data.user?.profile_image_url_https,
|
||||
};
|
||||
} catch (error: any) {
|
||||
return {
|
||||
success: false,
|
||||
markdown: '',
|
||||
url,
|
||||
error: `Syndication error: ${error.message}`,
|
||||
};
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Build markdown from FXTwitter API response
|
||||
*/
|
||||
private buildMarkdownFromFxTweet(tweet: any, originalUrl: string): string {
|
||||
const author = tweet.author?.name
|
||||
? `${tweet.author.name} (@${tweet.author.screen_name})`
|
||||
: 'Unknown';
|
||||
|
||||
let md = `---\nurl: "${originalUrl}"\nauthor: "${author}"\ncreated_at: "${tweet.created_at || ''}"\nlikes: ${tweet.likes || 0}\nretweets: ${tweet.retweets || 0}\nreplies: ${tweet.replies || 0}\n---\n\n`;
|
||||
|
||||
// Main text
|
||||
md += tweet.text + '\n';
|
||||
|
||||
// Media
|
||||
if (tweet.media?.photos?.length) {
|
||||
md += '\n';
|
||||
for (const photo of tweet.media.photos) {
|
||||
md += `\n`;
|
||||
}
|
||||
}
|
||||
|
||||
if (tweet.media?.videos?.length) {
|
||||
md += '\n';
|
||||
for (const video of tweet.media.videos) {
|
||||
md += `[Video](${video.url})\n`;
|
||||
}
|
||||
}
|
||||
|
||||
// Quote tweet
|
||||
if (tweet.quote) {
|
||||
const quoteAuthor = tweet.quote.author?.name
|
||||
? `${tweet.quote.author.name} (@${tweet.quote.author.screen_name})`
|
||||
: 'Unknown';
|
||||
md += `\n> **${quoteAuthor}:**\n`;
|
||||
md += `> ${tweet.quote.text?.replace(/\n/g, '\n> ')}\n`;
|
||||
}
|
||||
|
||||
return md;
|
||||
}
|
||||
|
||||
/**
|
||||
|
||||
@@ -0,0 +1,62 @@
|
||||
---
|
||||
url: "https://x.com/NVIDIAAIDev/status/2036928009366540789"
|
||||
requestedUrl: "https://x.com/NVIDIAAIDev/status/2036928009366540789"
|
||||
author: "NVIDIA AI Developer (@NVIDIAAIDev)"
|
||||
authorName: "NVIDIA AI Developer"
|
||||
authorUsername: "NVIDIAAIDev"
|
||||
authorUrl: "https://x.com/NVIDIAAIDev"
|
||||
tweetCount: 6
|
||||
---
|
||||
|
||||
## 1
|
||||
https://x.com/NVIDIAAIDev/status/2036928009366540789
|
||||
|
||||
🧵 We are expanding our open model families—including Nemotron, Cosmos, and BioNeMo—to advance development in agentic AI, physical AI, healthcare, and more. 👇 https://t.co/I5mjQN2fft
|
||||
|
||||

|
||||
[video](https://video.twimg.com/amplify_video/2036927885873684480/vid/avc1/1280x720/Swv4g6GGU6Mf7dnB.mp4?tag=14)
|
||||
|
||||
## 2
|
||||
https://x.com/NVIDIAAIDev/status/2036928019747467631
|
||||
|
||||
Access six frontier open model families on @HuggingFace to build your next specialized AI applications.
|
||||
|
||||
🤗 https://t.co/x6tMllfkzD https://t.co/FNWdDX3uAp
|
||||
|
||||

|
||||
|
||||
## 3
|
||||
https://x.com/NVIDIAAIDev/status/2036928025304936619
|
||||
|
||||
@huggingface Nemotron 3 Super is now a leading reasoning foundation for @OpenClaw 🦞 and complex agentic workflows, with 1.5M+ downloads in its first two weeks.
|
||||
|
||||
🤗 https://t.co/DSSLIXYIDz https://t.co/CMn1nxLvcH
|
||||
|
||||

|
||||
|
||||
## 4
|
||||
https://x.com/NVIDIAAIDev/status/2036928028970807406
|
||||
|
||||
@huggingface @openclaw For top reasoning accuracy across understanding, coding, and math benchmarks, Nemotron 3 Ultra (coming soon) sets a new efficiency standard for open models.
|
||||
|
||||
📰 https://t.co/zlDwhgcBY0 https://t.co/B8TigCuNp4
|
||||
|
||||
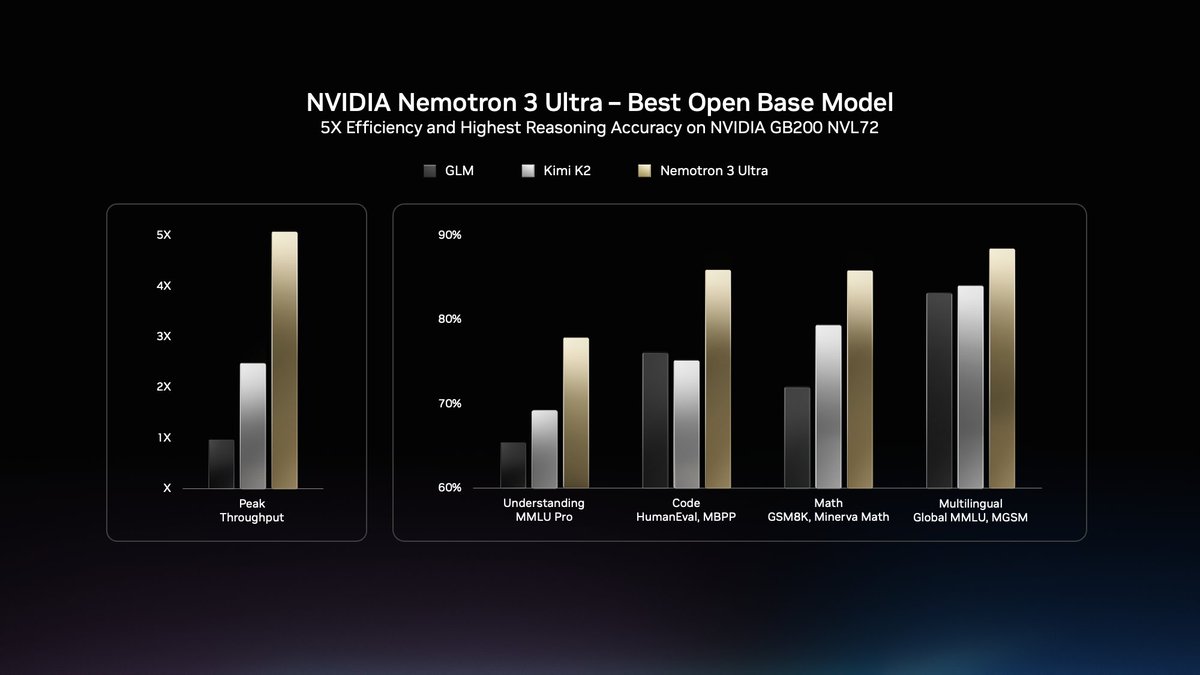
|
||||
|
||||
## 5
|
||||
https://x.com/NVIDIAAIDev/status/2036928032565313694
|
||||
|
||||
@huggingface @openclaw You can leverage Nemotron frameworks and persona data to build sovereign AI models tailored to regional languages and local cultural values.
|
||||
|
||||
🤗 https://t.co/RDC4Arh0JV https://t.co/aNbkg0GyCY
|
||||
|
||||
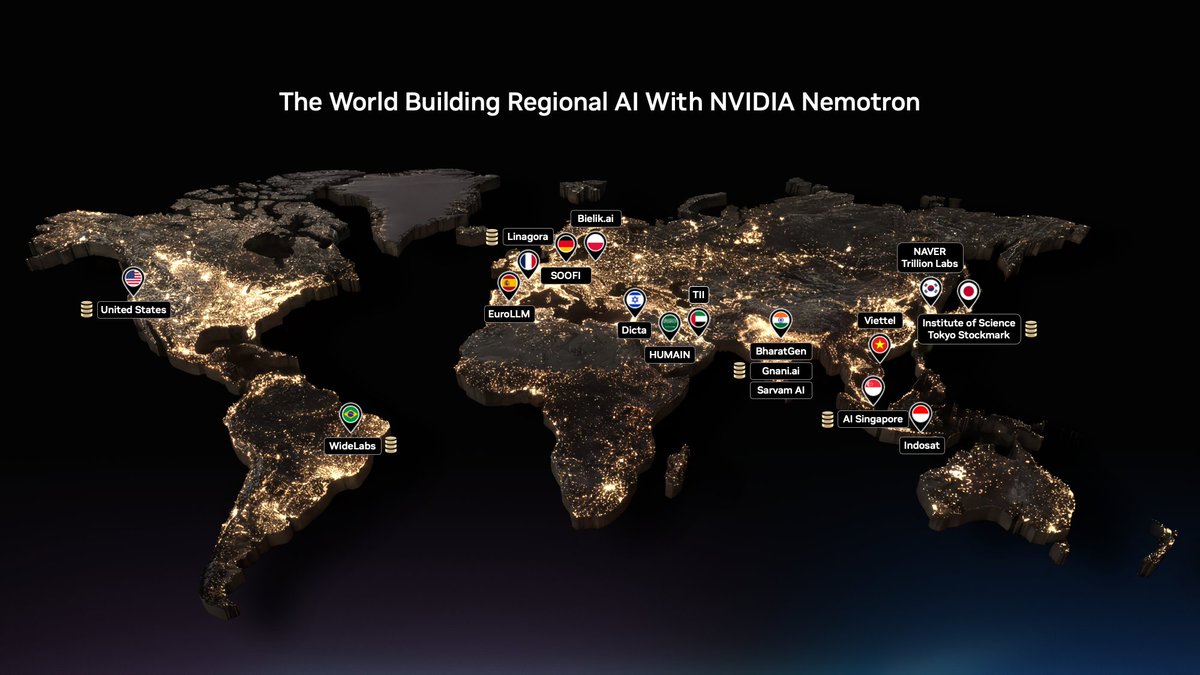
|
||||
|
||||
## 6
|
||||
https://x.com/NVIDIAAIDev/status/2036928036742762698
|
||||
|
||||
@huggingface @openclaw Access the full family of our open model weights and technical documentation on @HuggingFace to accelerate your specialized domain research.
|
||||
|
||||
🤗 https://t.co/x6tMllfkzD https://t.co/VJaL0NgRSj
|
||||
|
||||
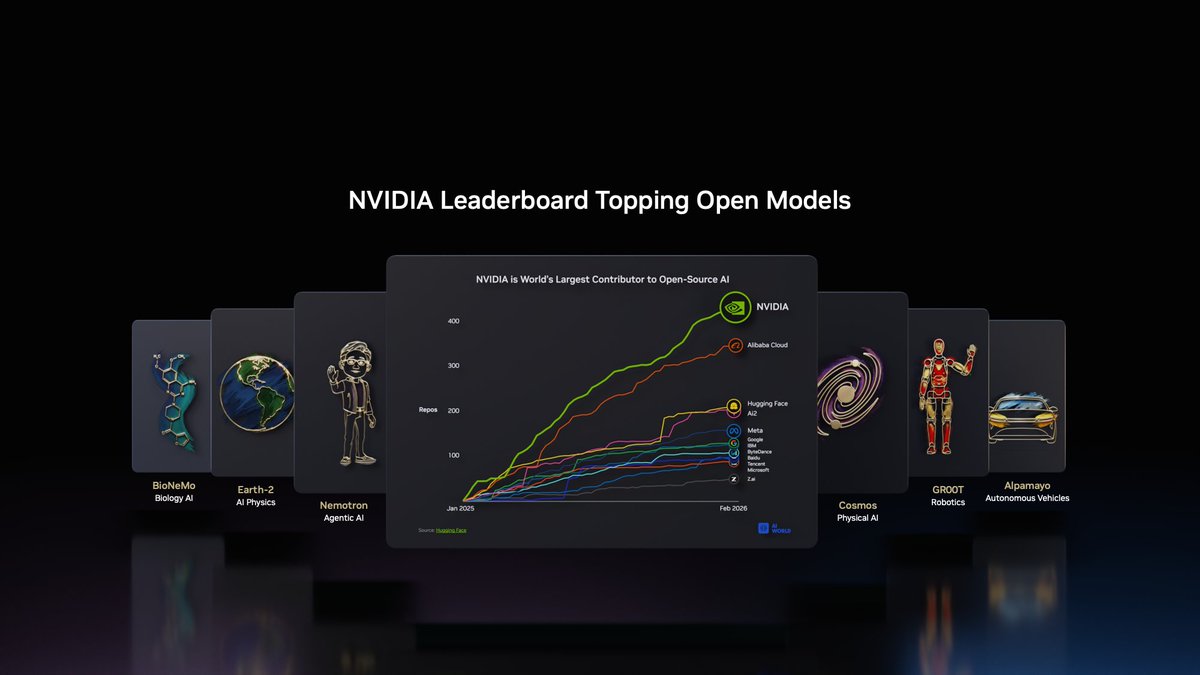
|
||||
Reference in New Issue
Block a user